解决Python爬取百度页面出现中文乱码问题 |
您所在的位置:网站首页 › 帝国时代 百度网盘链接下载 › 解决Python爬取百度页面出现中文乱码问题 |
解决Python爬取百度页面出现中文乱码问题
|
开始跟着B站上学习爬虫,使用的工具是PyCharm。
视频链接:https://b23.tv/NLp4gz6?share_medium=android&share_source=qq&bbid=XYC5605C8F19F10D959B8A59F386FD514EF41&ts=1640697988835
爬虫代码如下:
# -*- coding: utf-8 -*-
# 爬虫:本质是通过 编写程序 来获取到互联网上的资源
# 百度
# 需求:用程序模拟浏览器,输入一个网址,从该网址中获取到资源或内容
from urllib.request import urlopen # request表示请求库, urlopen打开一个网址
url = "http://www.baidu.com"
resp = urlopen(url) # 打开网址,得到响应
# resp.read() # 从响应中读取内容
# print(resp.read()) # b''表示字节
# print(resp.read().decode("utf-8"))
with open("mybaidu.html", mode="w") as f:
f.write(resp.read().decode("utf-8"))
print("over!")
运行成功后,打开爬取到的html页面:  发现仍然没有效果。再根据网上说的将mode="w"改成mode=“wb”: 发现仍然没有效果。再根据网上说的将mode="w"改成mode=“wb”:  仍然不行。然后想到将decode(“utf-8”)去掉: 仍然不行。然后想到将decode(“utf-8”)去掉:  但是,又会报错: 但是,又会报错:  write()函数w模式下只能写入字符串数据,而不能写入字节类型的数据。
最终的解决办法: write()函数w模式下只能写入字符串数据,而不能写入字节类型的数据。
最终的解决办法:
最后想到去掉decode(“utf-8”)的同时,再将w模式改成wb模式,wb模式写入的就是字节类型。 |
 会发现里面的中文是乱码。 原本乱码的地方应该是中文:
会发现里面的中文是乱码。 原本乱码的地方应该是中文:  但该页面在记事本中打开却可以呈现出中文:
但该页面在记事本中打开却可以呈现出中文: 
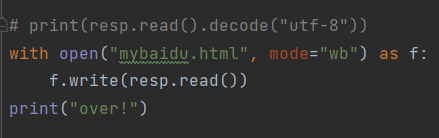 最后成功解决了爬取下来的页面在PyCharm中是中文乱码的问题。
最后成功解决了爬取下来的页面在PyCharm中是中文乱码的问题。 
【本文地址】
今日新闻 |
推荐新闻 |